
An Agentic Development Platform (ADP) is a platform built and operated by the platform engineering team that enables collaborative software development between engineers and AI agents. It provides the paths, interfaces, and guardrails that allow both humans and agents to work reliably at the autonomy levels set by the organization.

Figure 1: Agentic Development Platform end-to-end reference architecture with three layers: Tooling, path definitions, and agent infrastructure.
It’s been six years since we proposed the reference architectures for Internal Developer Platforms (IDPs). Since then, they’ve been downloaded over 250,000 times and have acted as the reference for many platforms (see latest versions of AWS, Azure and GCP). The revised guidance on ADP has been developed with this responsibility in mind, but is subject to change and constant iteration. We continue to build and assess platforms using these approaches and will revise as new insights emerge. Especially at the speed at which AI technologies are developing, this feels imperative. Note that our architectures are intended for enterprises with meaningful estate sizes, typically 50+ developers. If your instinct is “this feels like overkill,” you’re probably right, and you should ignore this architecture. Overautomation can hurt your productivity, too.
Final note on the naming. We call this “Agentic DevelopMENT Platforms” because we are increasingly observing business users vibe-code applications using advanced ADPs. We believe these user groups will account for a significant part of the user base going forward.
Three layers of an ADP
An ADP consists of three layers: Tooling, path definitions, and Agent Infrastructure. Tooling is the top layer, which contains the software tools and APIs needed to bring code to life. This layer is organized into five planes: developer control, integration & delivery, resource, security, and observability. Agent usage creates significant pressure on these tools to serve new requirements effectively. But they are, de facto, the same types of tools used in traditional IDPs designed for human users.
The middle layer contains the path definitions. Paths are what humans and agents invoke to get work done. Path definitions contain the information how the different parts of the ADP are supposed to execute those paths when invoked. Paths themselves come in three flavors: probabilistic (agent-driven, LLM-led work verified by evals and humans), deterministic (pipeline-driven, repeatable and gated, the CI/CD lineage you already know), and hybrid (the loop pattern of probabilistic step → deterministic gate → loop until passes). Paths are the unit of operation in an ADP.
The bottom layer is Agent Infrastructure. This layer is the constant substrate that makes agents operable across the platform. It covers the seven structural components every agent needs to function safely in an enterprise environment, including identity, context, capability, execution, evaluation, security, and observability.
One point worth clarifying upfront: deterministic paths run on the tooling layer alone. They predate the Agent Infrastructure and continue to operate independently of it. The Agent Infrastructure exists to make probabilistic and hybrid paths possible. This makes the ADP a true evolution of the IDP rather than a replacement for it. If you don’t yet have a good IDP, forget building an ADP. You need those clean foundations first. Which in turn does not mean the tooling layer becomes unnecessary once Agent Infrastructure is in place. Hybrid paths are situations in which probabilistic elements, such as agents, call deterministic paths. An ADP cannot exist without tooling.
The tooling layer
The top layer is the muscles of the ADP, consisting of the five planes we proposed for structuring the reference architecture for IDPs. The Developer Control Plane for surfaces and knowledge (Backstage, Port, VS Code, Cursor, IntelliJ, Jira, Linear, Confluence, Notion). The Integration & Delivery Plane for source, build, and ship (GitHub, GitLab, Jenkins, ArgoCD, Terraform). The Resource Plane where software runs (Kubernetes, AWS, GCP, Azure, Snowflake). The Security Plane for tests, scans, and gates (Jest, Pytest, Snyk, SonarQube, Trivy, Semgrep). The Observability Plane for production app signals (Datadog, Grafana, Honeycomb, Splunk, Kubecost).
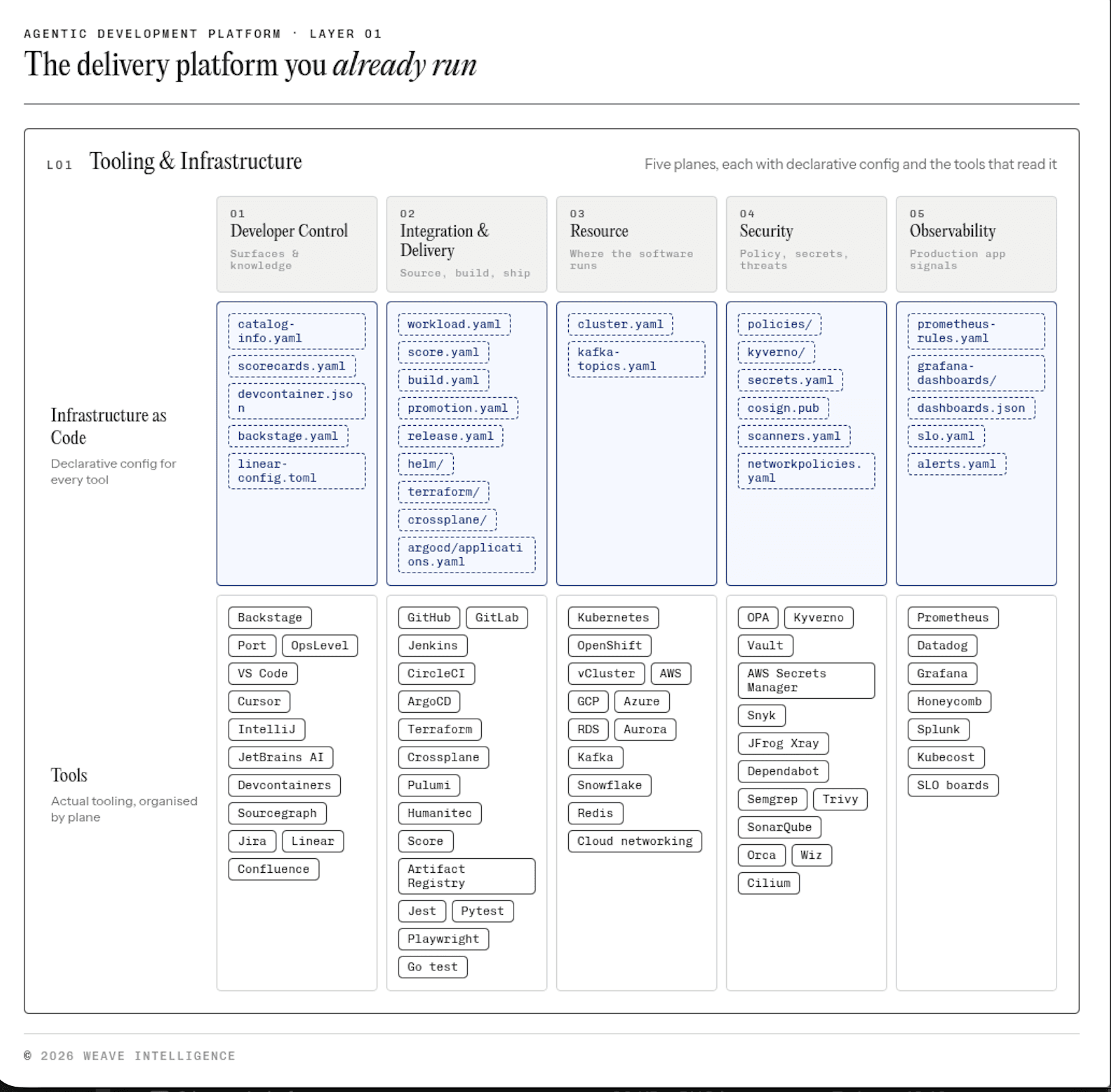
Figure 2: Zoom in on the Tooling layer, showing the five planes: developer control, integration & delivery, resource, security, and observability.
These are largely the tools platform teams have been building and curating for years. What changes is the demand placed on them. Agents call tools repeatedly, in parallel, at volumes no human workflow anticipates. Tools designed for deliberate sequential human interaction need to evolve with reliable APIs, predictable rate limits, structured outputs, and clear failure modes. Platform engineers must make that case to vendors and internal teams alike.
Building on the guidance we’ve always given on the IDP design, configuration as code remains non-negotiable at enterprise scale. The tooling layer is backed by Infrastructure as Code (IaC): declarative configuration for every tool, defined in files like backstage.yaml, pipelines.yaml, terraform/, and policies/. It’s the same discipline platform engineers have been practicing for years.
The path definitions layer
Platform engineering has always been about paths. The term was first coined by Charity Majors, and we've built on it ever since, because it's a brilliant way of thinking about what platforms actually do. A path is a valuable way for a user to achieve an outcome and progress along a value stream. While shipping a feature is a value stream, examples for paths could be creating an ephemeral environment, raising a PR, running a security scan, and deploying to production.
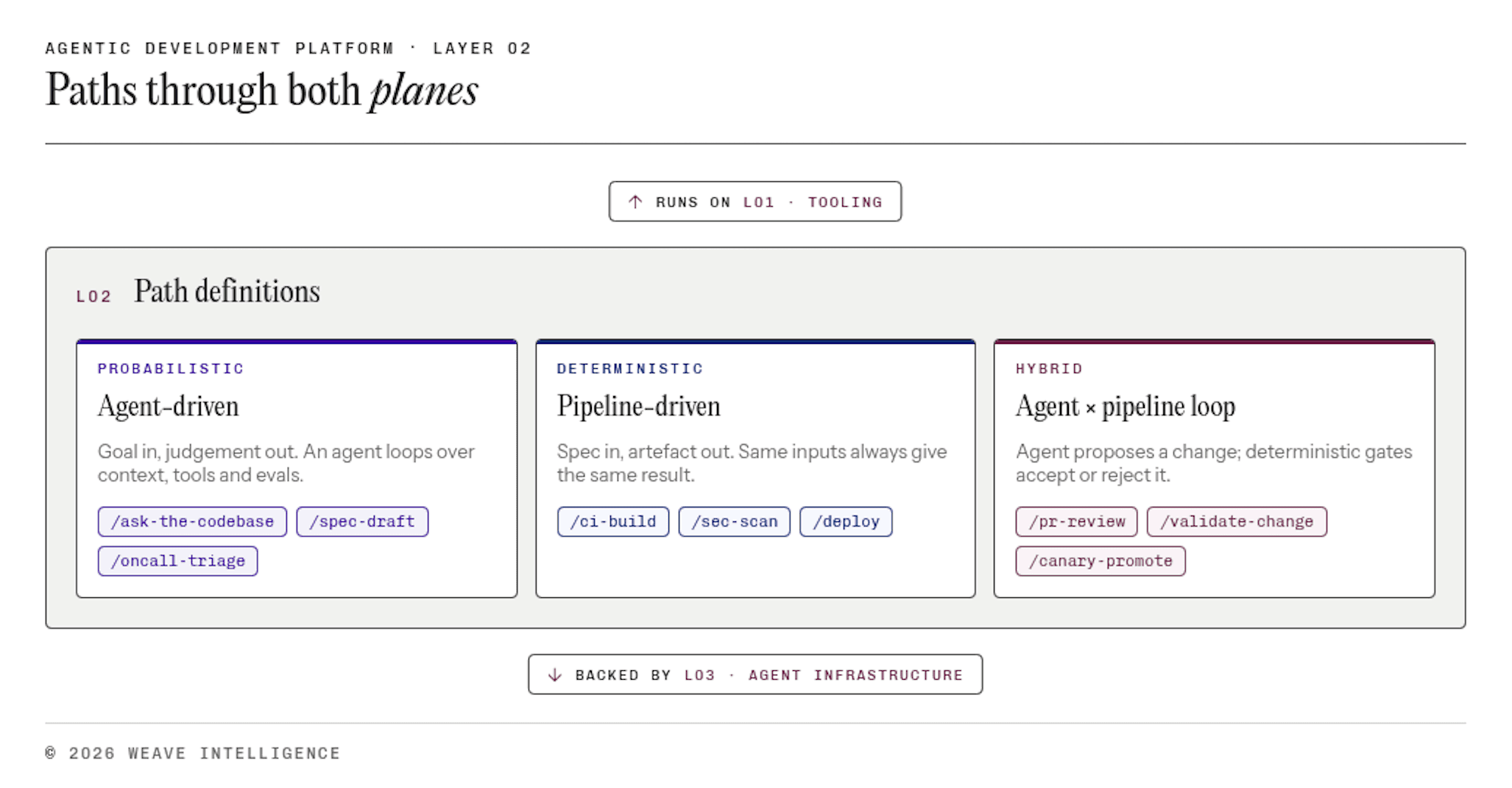
Figure 3: Zoom in on the Path Definitions layer, showing the three path types: probabilistic, deterministic, and hybrid.
In an ADP, paths become more important, not less. Because if you think about it, an agent is simply another type of user. Agents join the fun circle of building platforms with many of the same operational needs as human users. They too need good documentation, well-designed interfaces, and clear capability boundaries to operate safely.
Path definitions describe how the different parts of the ADP execute a path when it is invoked. The definition is not the runtime; execution is handled by the orchestrator in the Agent Infrastructure layer. Paths themselves come in three types:
Probabilistic paths are agent-driven. The LLM does the work and outcomes are verified by evals and humans. An agent reviewing a pull request, drafting a first-pass spec from a ticket, or generating release notes from merged changes are all probabilistic paths. The definition specifies the LLM-driven steps, the eval criteria, and the human verification points.
Deterministic paths are pipeline-driven. Platform engineers have been building them forever. Repeatable, gated, codified. CI builds, security scans, deployments, policy gates, promotions. These are exactly the paths your IDP already runs. The definition describes the repeatable steps, gates, and promotion rules the CI pipeline will execute.
Hybrid paths combine the two in a loop pattern. A probabilistic step produces a candidate, a deterministic gate evaluates it. The loop continues until the gate passes. An agent proposes a change, the pipeline validates it, failures route back to the agent, the agent retries. This loop pattern is where the real productivity gains and accuracy come from. The mistake is to assume it's problematic if an agent fails on the first run, rather than structuring the platform so that repeated runs against error-updated context converge on the correct result. This is similar to finding the global maximum of a function in basic algebra.
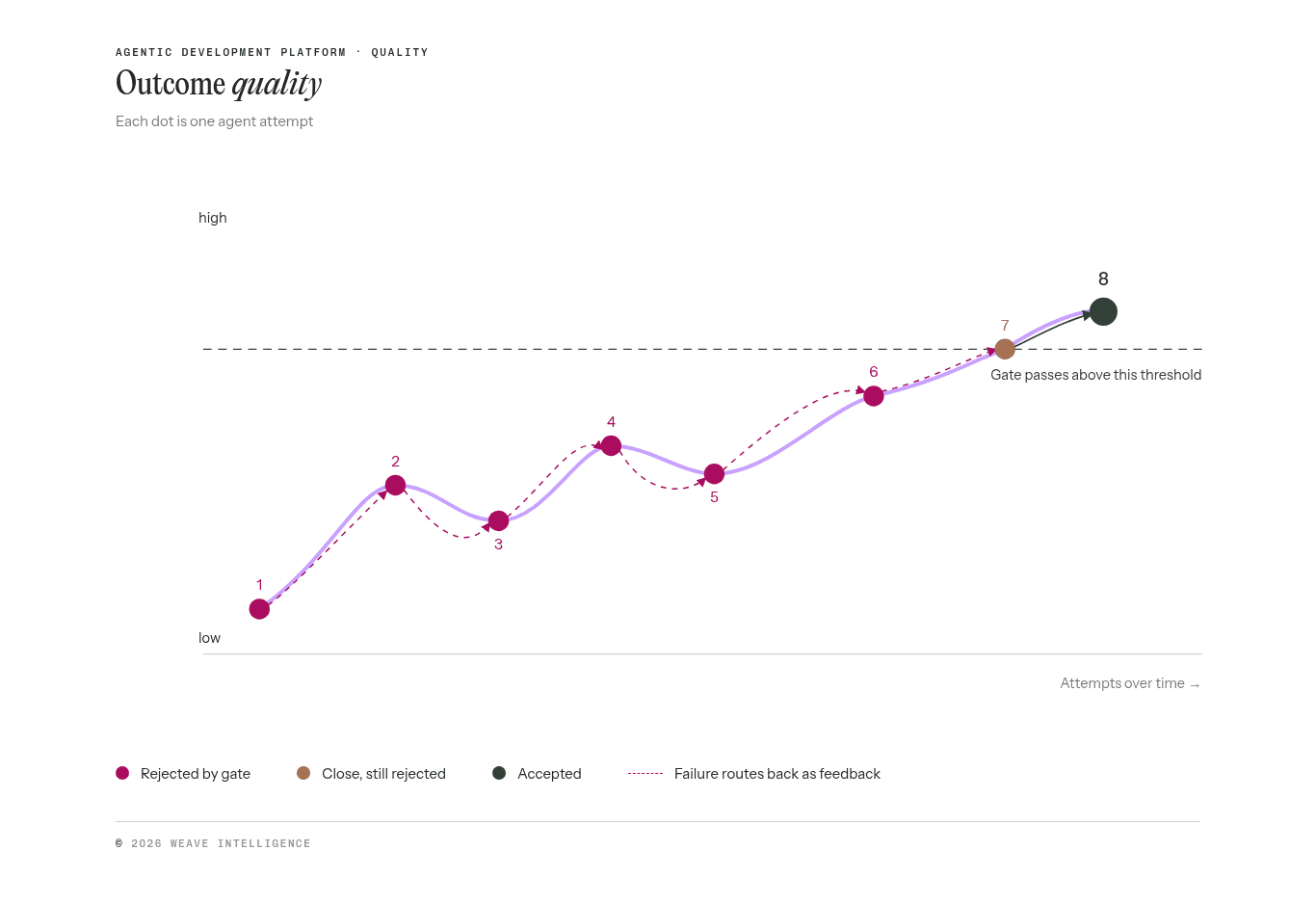
Figure 4: Outcome quality across agent attempts over time, showing how failure routes back as feedback until the gate passes.
The Agent Infrastructure layer
The Agent Infrastructure layer is the constant substrate of the ADP. It is the scripts and infrastructure that run agents, tune agent behavior, supply context and memory among other things, define guardrails, and govern how humans and agents communicate. If we focus on this layer, we again need to differentiate the actual infrastructure from its representation as code. We call this practice Agent Infrastructure as Code (AIaC). Platform engineers who already practice IaC will recognize the pattern. Same discipline, expanded scope, and absolutely vital for recoverability, auditability, and all the usual benefits of "as code" approaches.
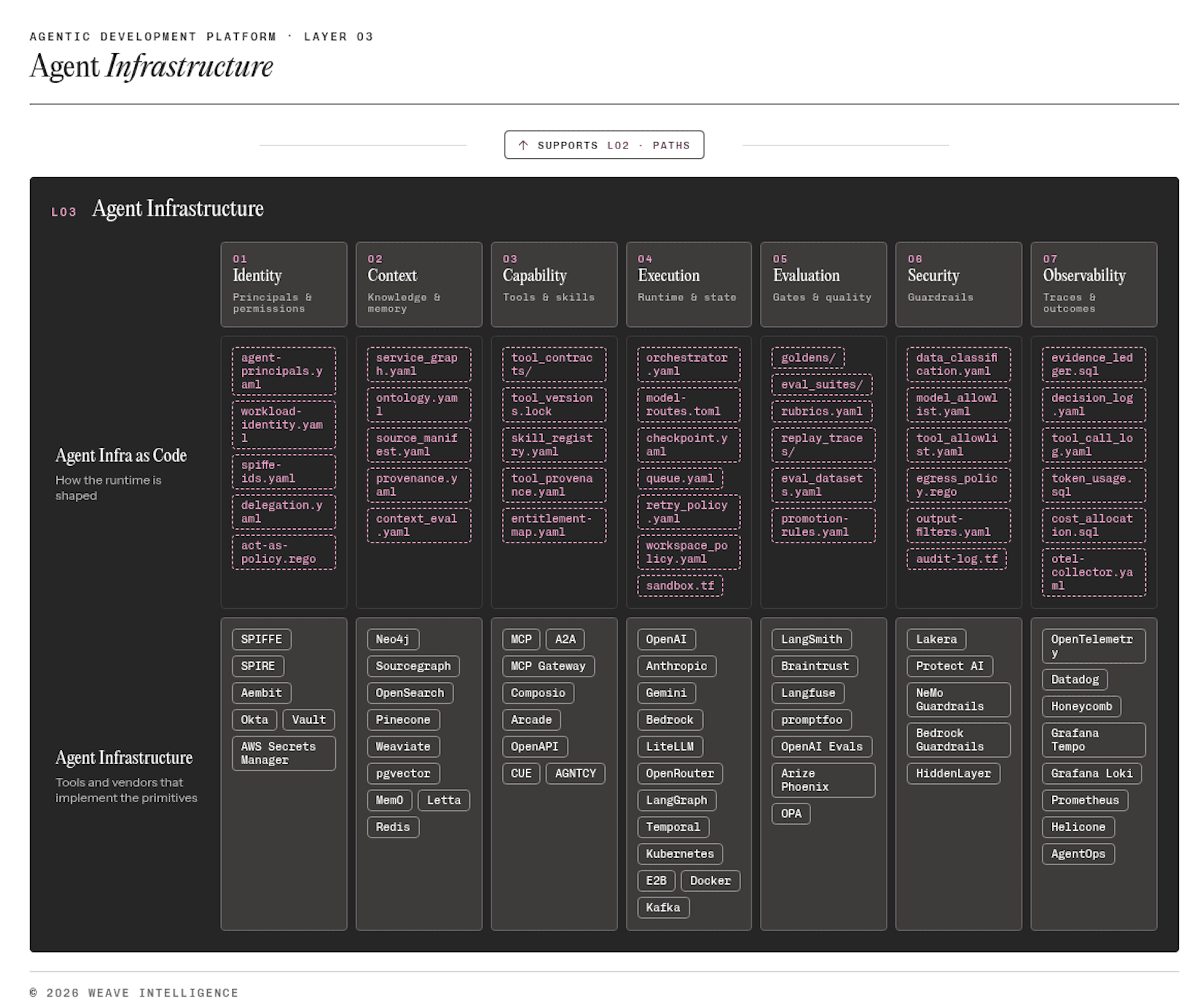
Figure 5: Zoom in on the Agent Infrastructure layer that shows the actual infrastructure and the overlaying Agent Infrastructure as Code layer.
This layer has seven components: identity, context, capability, execution, evaluation, security, and observability. Together they answer the questions every enterprise must resolve before granting agents meaningful autonomy: who is acting, what are they allowed to do, what does the agent know, where does it run, was the output acceptable, is the system protected against misuse, and what happened afterward?
Identity defines principals and permissions. In the end, agents can be understood as another type of user, and every user requires clear authentication and authorization to act within defined permission boundaries. Agents must be credentialed, their scope bounded, their budgets constrained, and their egress controlled. Without these controls, the platform cannot reason about accountability at scale.
Context gives agents what they need to act correctly, through context assets, retrieval, telemetry as context, and memory tiers. These foundations are vital because agents without sufficient information do not fail loudly; they proceed on incomplete assumptions.
Capability exposes what agents can do through a tool registry, Model Context Protocol (MCP) gateway, entitlement map, and skill registry. At this point, much of the existing IDP capability estate carries over. If your organization has already built mature infrastructure paths, they are exposed here for the agents to use.
Execution manages runtime and state, and performs the actual work. They model themselves, the model router, the orchestrator, ephemeral workspaces, and session management. Autonomy becomes real, and the risks of runaway agents are either contained or left unchecked.
Evaluation provides the gates and quality layer including policy as code, tests, promotion and rollback rules, and probabilistic evals. It is what separates a platform an organization can trust from one it can only hope works.
Security is the guardrails and threat surface layer, such as prompt firewall, output guard, data egress controls, risk scoring, and jailbreak detection.
Observability captures what happened and what the organization learned inlcuding traces, dashboards, outcomes, context feedback, and costs.
This layer is not specific to software development. The same substrate is needed to build Agentic Marketing Platforms, Agentic Sales Platforms, and Agentic Finance Platforms. Because these teams are not capable of architecting and maintaining agentic infrastructure themselves, this is ultimately the job of platform engineers. There is far more to explore here, given the significant implications for platform engineering as a discipline.

Figure 6: The Agent Infrastructure layer as a shared substrate for vertical agentic platforms across engineering, marketing, sales, and finance.
How a path actually runs
To make this concrete, we walk through what happens when an agent runs a probabilistic path like `/pr-review`.
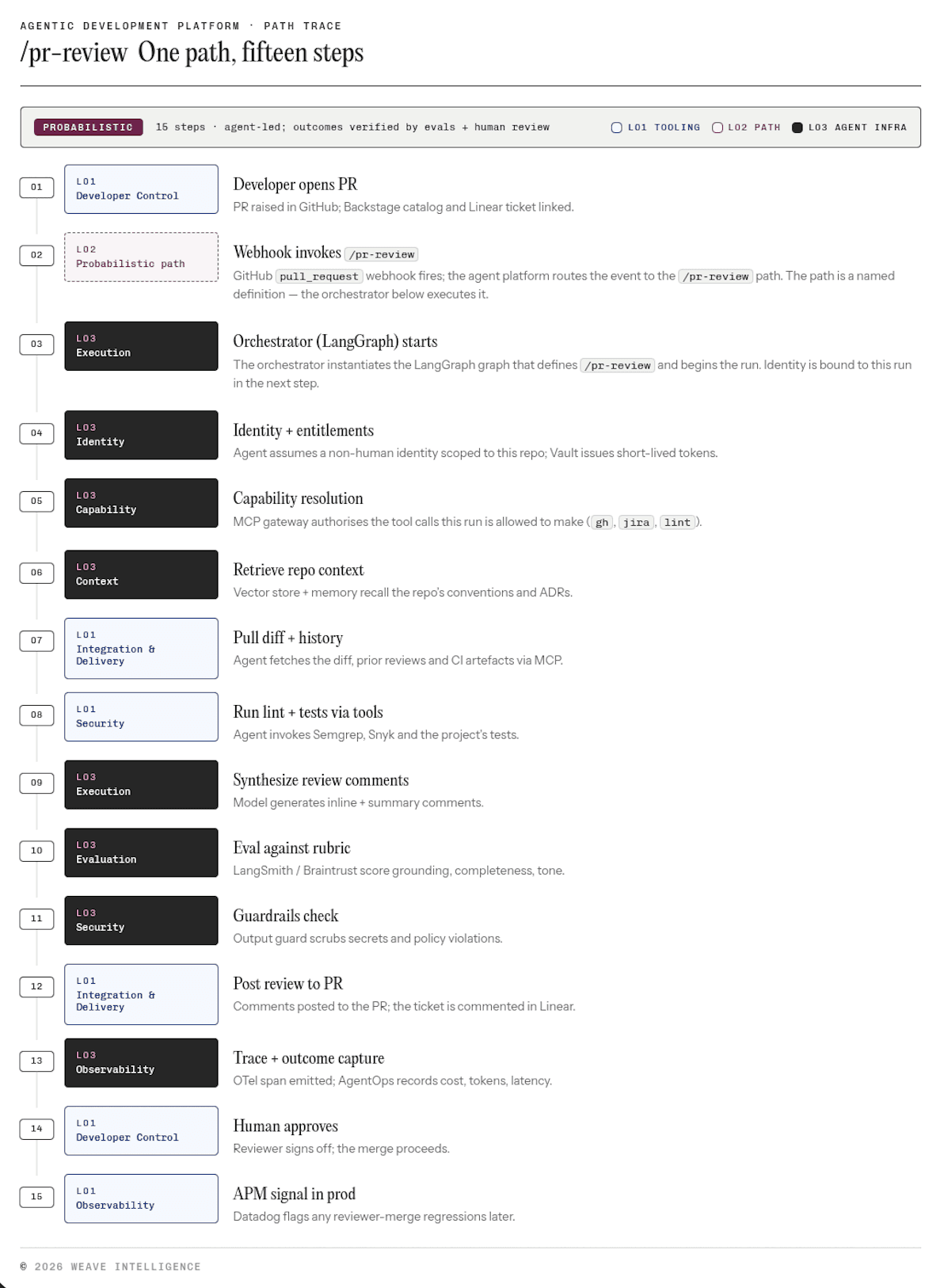
Figure 7: End-to-end walk-through of the /pr-review probabilistic path, showing how identity, context, capability, execution, evaluation, security, and observability each activate in sequence.
A developer opens a PR in GitHub. Because we're good citizens, the change is linked back to the Backstage catalog and a Linear ticket. That's what triggers the path. GitHub fires a `pull_request` webhook, and the agent platform routes the event to the named `/pr-review` path. `/pr-review` is a definition, not a runtime. It describes the work, but something else must execute it.
That something is the orchestrator. In our reference stack, that's LangGraph, a workflow engine that sequences steps, manages state between them, handles retries, and persists progress. It's important to be precise here. The orchestrator does not think; it walks a graph. The reasoning happens inside the LLM nodes the graph contains, and the model's output can drive which edge gets taken next. That’s what makes the path probabilistic rather than deterministic. The orchestrator is structurally similar to Temporal or Argo Workflows, except some of its nodes are allowed to be LLM calls, and those calls are allowed to influence control flow.
Once the orchestrator instantiates the graph for `/pr-review`, the run needs an identity. The agent assumes a non-human identity scoped to that repository, with short-lived tokens issued by Vault or equivalent. Identity must bind first, because nothing further can be authorized without a principal.
With identity bound, the run resolves capability. The MCP gateway looks up which tools this identity is entitled to call (gh, jira, lint, project tests) and surfaces them to the agent. Capability has to come before any tool use, including retrieval, because retrieval itself often goes through the gateway.
Now the agent can pull context. Vector and memory layers recall the repo's conventions and Architecture Decision Records (ADRs). The agent fetches the diff, prior reviews, and CI artefacts. With the working set loaded, the agent invokes its tools, runs lint, runs tests via Semgrep, Snyk, and the project's own suite, and synthesizes inline plus summary review comments grounded on the diff and that context.
Then the gates. An eval node scores the output against a rubric (grounding, completeness, tone) using LangSmith or Braintrust. A guardrails node scrubs secrets and policy violations on the egress path. Only then does the review get posted back to the PR.
After the post, observability captures the trace. The OTel span, cost, tokens, latency, and pass/fail outcome are all recorded. Application Performance Monitoring (APM) picks up any reviewer-merge regressions later, and the result lands with the human reviewer for sign-off.
That single path touches every pillar of the Agent Infrastructure. Identity at the start. Context and capability before any tool use. Execution while the work happens. Evaluation and security at the gates. Observability throughout. You can do all of this with Claude Code on a laptop without any of this infrastructure, and you should, because that’s how you learn the shape of it. But not at enterprise scale. At scale, every one of these pillars must exist, be defined as code, and be owned by the platform engineering team. If that is not the case, it won’t be possible to meet the security, audit, and quality requirements of modern enterprises.
The ADP grows with the level of autonomy you grant
The maturity your ADP requires depends on where your organization sits on the maturity curve. In our research on the four levels of agentic software development, we define each level by the changing role of the human across the feature development value stream, from human-in-the-loop at Level 1 to full autonomy at Level 4.
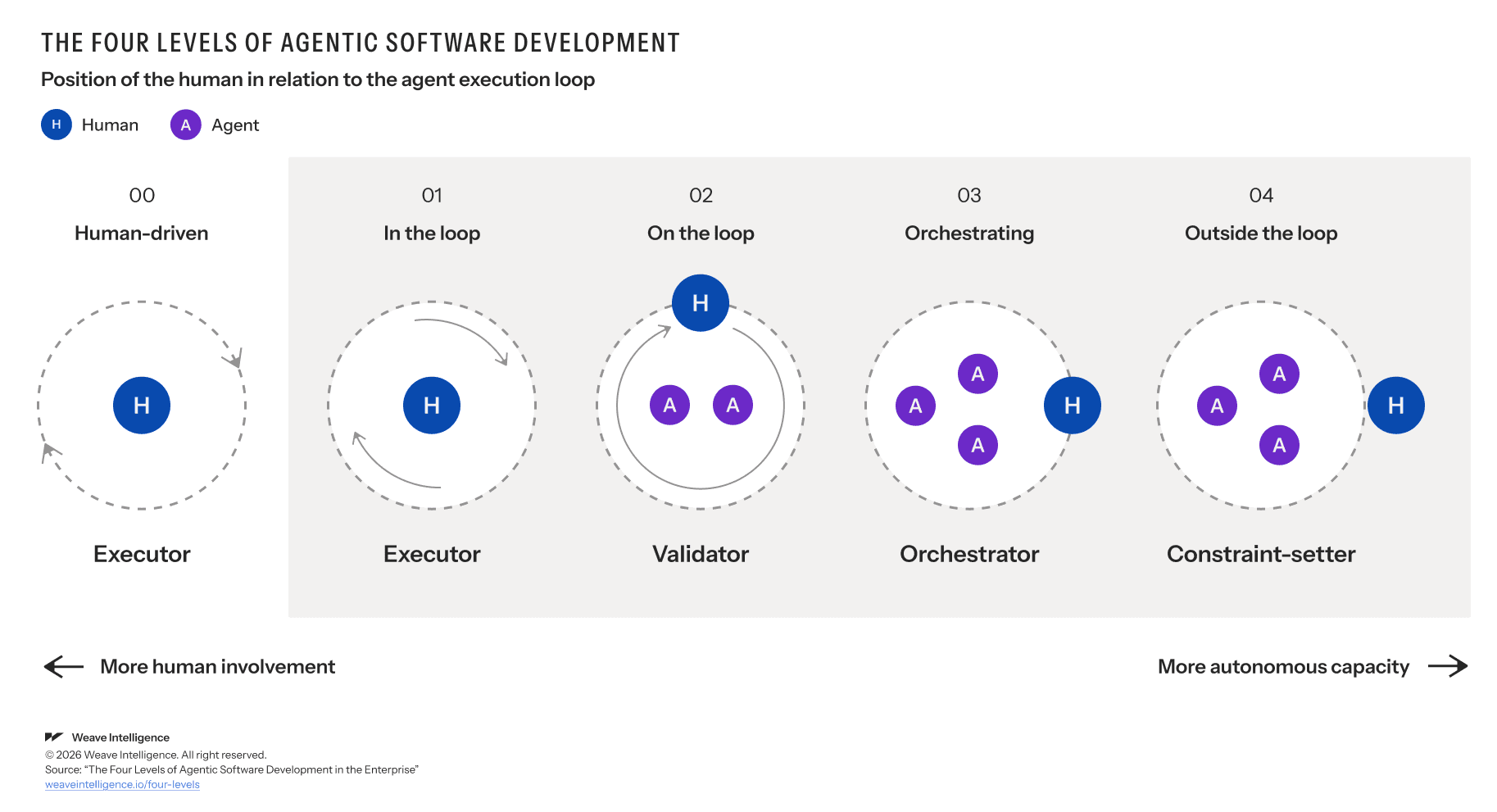
Figure 8: The four levels of agentic software development
At Level 1, the Agent Infrastructure can be minimal. Agents assist inside the Integrated Development Environment (IDE) and humans catch errors. Most paths are still deterministic, with a handful of experimental probabilistic paths like /pr-review or /release-notes appearing at the edges.
By Level 2, when agents start producing pull requests in parallel and validation becomes a feedback loop rather than a single gate, identity, workspace provisioning, evaluation, and security all become non-negotiable. New probabilistic paths appear (/spec-draft), and the first hybrid loop paths like /validate-change come online.
By Level 3, the full substrate must be operational. Heavy investment in /pr-review, /spec-draft, /release-notes, plus new paths like /oncall-triage and /groom-backlog. Hybrid paths become far more common. This is where most forward-thinking organizations will be in a year from now. The platform I work with every day is at Level 3 90% of the time.
Level 4 is fully autonomous. Paths respond to signals rather than human triggers: a vulnerability is detected and automatically remediated. A customer call transcript mentioning a frontend bug is automatically fixed and shipped. Signal management becomes its own discipline at this level. Telemetry systems are becoming more important. Organizations that attempt Level 3 with a Level 1 substrate will find their agents running faster than their guardrails can keep up.
You don’t need to build everything today. But you need to know what the next level demands before you attempt the transition. The most common failure mode we see isn’t models that cannot perform, but a platform unable to deal with the complexity of at-scale agentic operation.
It’s early days, but we are already seeing teams deploy Agentic Development Platforms with Level 3 and even partial Level 4 autonomy. We’re convinced this is the future of software engineering. Our upcoming research will double down on the Agent Infrastructure layer to dissect the nuts and bolts, and cover in detail how to transform your current setup into a scalable ADP step by step. The organizations that move on this early will not just ship faster. They will operate on a different curve entirely.
Disclaimer: In this article, we mention representative vendors for certain categories. Weave Intelligence doesn’t endorse any vendors, and the mentions are purely illustrative.